
생각하는 감쟈
[Python] 4-1) 머신러닝 기초 본문
18일차 (23.04.05)

ml: 머신러닝
- 데이터에서 지식을 추출하는 작업
- 통계학 인공지능 컴퓨터 과학이 얽혀있는 연구 분야
- 예측분석, 통계적 머신러닝
머시러닝을 사용한 애플리케이션
- 영화추천 음식 주문 쇼핑 맞춤형 온라인 라디오 방송
- 사진에서 친구 얼굴을 찾아주는 앱
- 페이스북, 아마존, 넷플릭스
가장 많이 사용되는 머신러닝 알고리즘
- 일반화 된 모델을 만들어 의사 결정 프로세스를 자동화 하는것 (지도학습)
- 사용자 - 알고리즘에 입력과 기대되는 출력을 제공
- 알고리즘 - 주어진 입력에서 원하는 출력을 만드는 방법 찾기
- 학습된 알고리즘 - 사람의 도움 없이도 새로운 입력이 주어지면 저절한 출력 생성 가능
지도학습 알고리즘
- 입력과 출력으로 학습하는 머신러닝 알고리즘
머신러닝 알고리즘
- 아무런 정보가 없는 데이터로는 그 어떤 것도 예측할 수 없음
머신로닝 프로세스에서 가장 중요한 과정
- 사용할 데이터를 이해하고 문제와 관려성 이해하기
- 알고리즘 마다 적합한 데이터나 문저의 종류에 차이
머신러닝 솔루션
- 어떤 질문을 대한 답을 원하는가?
- 내질문을 머신러닝의 문제를 가장 잘 기술하는 방법은 무엇인가?
- 문제를 풀기에 충분한 데이터를 모았는가?
- 내가 추출한 데이터의 특성은 무엇임, 좋은 예측을 만들어 낼 수 있는 것인가?
- 머신러닝 애플리케이션의 성과를 어떻게 측정할 수 있는가?
- 머신러닝 솔루션이 다른 연구나 제품과 어떻게 협력할 수 있는가?
머신러닝 알고리즘
- 특정 문제를 푸는 전체 과정의 일부일 뿐
- 시스템에 대한 큰 그림을 그려야 함
- 머신러닝 모델 구출 시 직간접적인 가능한 모든 가정
import numpy as np
x=np.array([[1,2,3],[4,5,6]])
print("x:\n",x)x:
[[1 2 3]
[4 5 6]]from scipy import sparse
eye = np.eye(4)
print("NumPy 배열 :\n", eye)NumPy 배열 :
[[1. 0. 0. 0.]
[0. 1. 0. 0.]
[0. 0. 1. 0.]
[0. 0. 0. 1.]]sparse_matrix = sparse.csr_matrix(eye)
print("\nScipy의 csr 행렬:\n",sparse_matrix)Scipy의 csr 행렬:
(0, 0) 1.0
(1, 1) 1.0
(2, 2) 1.0
(3, 3) 1.0
data = np.ones(4)
row_indices = np.arange(4)
col_indices = np.arange(4)
eye_coo = sparse.coo_matrix((data,(row_indices, col_indices)))
print("coo 표현:\n", eye_coo)coo 표현:
(0, 0) 1.0
(1, 1) 1.0
(2, 2) 1.0
(3, 3) 1.0%matplotlib inline
import matplotlib.pyplot as plt
x=np.linspace(-10,10,100)
y=np.sin(x)
plt.plot(x,y,marker="x")
import pandas as pd
data={'name':["john","Anna","Petter","Linda"],
'Location':["New York","Paris","Berlin","London"],
'Age':[24,13,53,33]}
data_pandas = pd.DataFrame(data)
data_pandas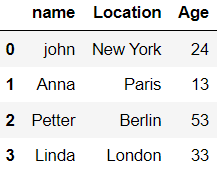
data_pandas[data_pandas.Age>30]
밑에 4개 코드는 시작하면 무조건 적고 시작!
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearnimport sys
print("Python 버전", sys.version)
import pandas as pd
print("pandas 버전", pd.__version__)
import matplotlib
print("matplotlib 버전", matplotlib.__version__)
import numpy as np
print("Numpy 버전", np.__version__)
import scipy as sp
print("Scipy 버전", sp.__version__)
import IPython
print("Numpy 버전", IPython.__version__)
import sklearn
print("scikit-learn 버전", sklearn.__version__)pip 다운그레이드 명령어 예제
아나콘다 프롬프트창에서 다음과 같은 형식으로 버전을 기입
- 패키지명, 버전을 원하는 버전으로 기입
pip install --user -U scikit-learn==1.0.2
pip install --user -U joblib==1.1.0
pip install --user -U mglearn==0.1.9
pip install --user -U numpy==1.23.5
첫 번째 애플리케이션 :품종 분류
%matplotlib inline
from IPython.display import display
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.datasets import load_iris
iris_dataset = load_iris()
print("iris_dataset key:\n{}".format(iris_dataset.keys()))iris_dataset key:
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])print(iris_dataset['DESCR'][:193]+"\...").. _iris_dataset:
Iris plants dataset
--------------------
**Data Set Characteristics:**
:Number of Instances: 150 (50 in each of three classes)
:Number of Attributes: 4 numeric, pre\...print("target name: {}".format(iris_dataset['target_names']))target name: ['setosa' 'versicolor' 'virginica']print("eature names: \n{}".format(iris_dataset['feature_names']))eature names:
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']print("datad의 타입:{}".format(type(iris_dataset['data'])))datad의 타임:<class 'numpy.ndarray'>print("datad의 크기:{}".format(iris_dataset['data'].shape))datad의 크기:(150, 4)print("datad의 처음 다섯 행:\n{}".format(iris_dataset['data'][:5]))datad의 처음 다섯 행:
[[5.1 3.5 1.4 0.2]
[4.9 3. 1.4 0.2]
[4.7 3.2 1.3 0.2]
[4.6 3.1 1.5 0.2]
[5. 3.6 1.4 0.2]]print("target의 타입:{}".format(type(iris_dataset['target'])))target의 타입:<class 'numpy.ndarray'>
print("target의 크기:{}".format(iris_dataset['target'].shape))target의 크기:(150,)
print("타깃\n{}".format(iris_dataset['target']))타깃
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]성과측정
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(
iris_dataset['data'],iris_dataset['target'],random_state=0)print("X_train 크기",x_train.shape)
print("y_train 크기",y_train.shape)X_train 크기 (112, 4)
y_train 크기 (112,)print("X_test 크기",x_test.shape)
print("y_test 크기",y_test.shape)X_test 크기 (38, 4)
y_test 크기 (38,)iris_dataframe = pd.DataFrame(x_train, columns=iris_dataset.feature_names)pd.plotting.scatter_matrix(iris_dataframe,c=y_train, figsize=(15,15),marker='o',
hist_kwds={'bins':20},s=60,alpha=.8,cmap=mglearn.cm3)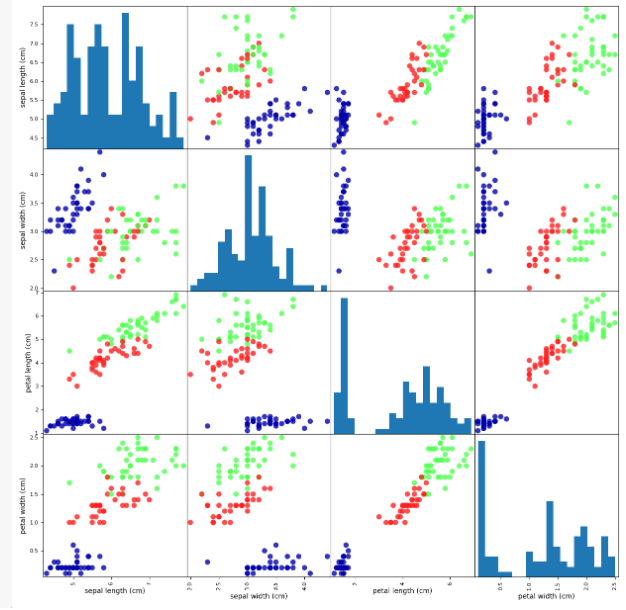
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1)knn.fit(x_train,y_train)KNeighborsClassifier(n_neighbors=1)
x_new = np.array([[5,2.9,1,0.2]])
print("x_new.shape:",x_new.shape)x_new.shape: (1, 4)prediction = knn.predict(x_new)
print("prediction:",prediction)
print("name:",iris_dataset['target_names'][prediction])prediction: [0]
name: ['setosa']y_pred = knn.predict(x_test)
print("예측 값:\n",y_pred)예측 값:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0
2]print("정확도:{:.2f}".format(np.mean(y_pred == y_test)))
print("정확도:{:.2f}".format(knn.score(x_test, y_test)))정확도:0.97
지도학습
가장 널리 성공적으로 사용되는 머신러닝 방법 중 하나
입력과 출력 샘플 데이터가 있고, 주어진 입력으로 부터 출력을 예측하고자 할떄
입력/출력 샘플데이터로 부터 모신러닝 모델을 생성
분류(Classification)
- 미리 정의된 가능성 있는 여러 클래스레이블 중 하나를 혜측
- 이진 분류
- 질문의 답이 예/아이요
- 이메일에서 스팸을 분류하는 방법
- 다중 분류
- 붓꽃 분류
- 웹 사이트에서 사용하는 언어 분류하기
회귀(Regression)
- 연속적인 숫자 또는 실수(부동소수점)를 예측
- 예상 출력 값 사이에 연속성이 있음
- 어떤 사람의 연봉 예측 : 4천과 ,4천1만원은 큰 문제 x
일반화, 과대적합, 과소적합
일반
훈련 데이터로 학습한 모델
- 훈련데이터와 특성이 같다면 처음보는 새로운 데이터가 주어져도 정확히 예측으로 가대
일반화
- 모델이 처음 보는 데이터에 대해 정확하게 예측 가능
- 모델 설계사 가능한 정확히 일반화되도록 하는 것이 목표
일반화가 어려움
- 아주복잡한 모델 설계 시 훈련 세트에만 정확한 모델이 되어버릴 수 있음
과대적합 과 과소적합
알고리즘이 새로운 데이터도 잘 처리하는지 확인하는 방법
- 데스터 세트로 평개해보는 수 밖에 없음
- 간단한 모델이 새로운 데이터에 더 잘 일반화
과대적합
- 모델이 휸련세트의 각 샘플에 너무 가깝게 맞춰져서 새로운 데이터에 일반화 된기 어려움
ex) 45세 이상이고 자녀가 셋 미만이며 이혼하지 않은 고객은 요트를 산다
과소적합
- 모델이 너무 가단해서 데이터의 다양성을 잡아내지 못하는 문제
ex) 집이 있는 사람은 모두 요트를 사려고 한다
X,y = mglearn.datasets.make_forge()
mglearn.discrete_scatter(X[:,0],X[:,1],y)
plt.legend(["클래스 0","클래스 1"], loc=4)
plt.xlabel("첫 번째 특성")
plt.ylabel("두 번째 특성")
print("X.shape:",X.shape)
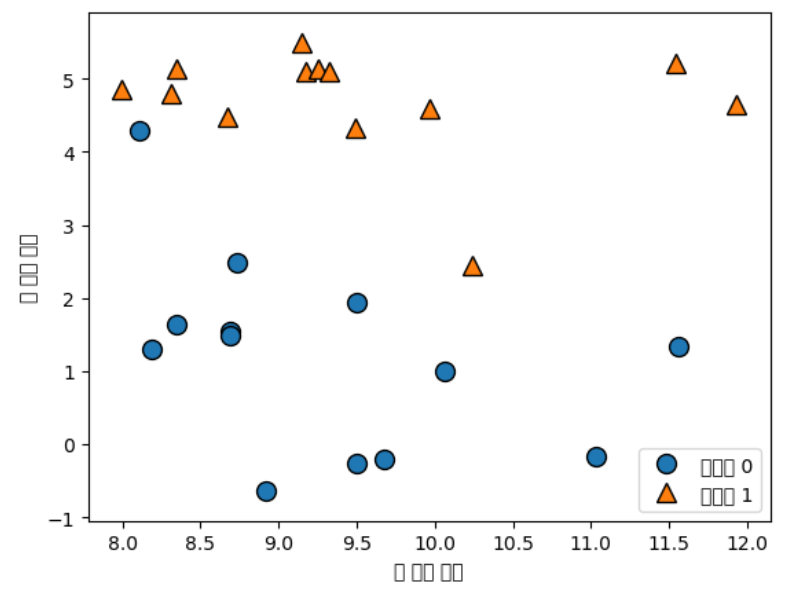
X,y = mglearn.datasets.make_wave(n_samples=40)
plt.plot(X,y,'o')
plt.ylim(-3,3)
plt.xlabel("f")
plt.ylabel("t")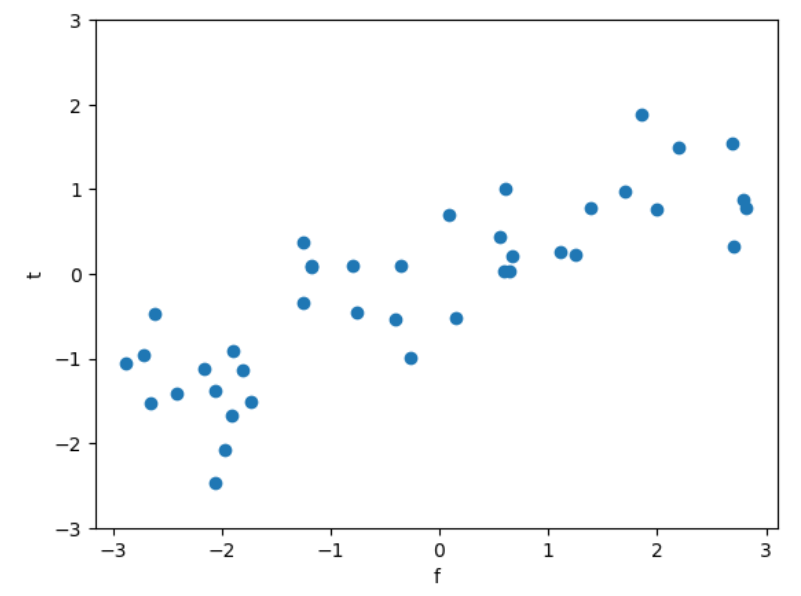
유방암 데이터
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print("cnacer.keys():\n",cancer.keys())cnacer.keys():
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module'])print("유방암 데이터의 형태:",cancer.data.shape)유방암 데이터의 형태: (569, 30)print("클래스별 샘플 개수:\n",{n:v for n,v in zip(cancer.target_names, np.bincount(cancer.target))})클래스별 샘플 개수:
{'malignant': 212, 'benign': 357}print("특성이름:\n",cancer.feature_names)특성이름:
['mean radius' 'mean texture' 'mean perimeter' 'mean area'
'mean smoothness' 'mean compactness' 'mean concavity'
'mean concave points' 'mean symmetry' 'mean fractal dimension'
'radius error' 'texture error' 'perimeter error' 'area error'
'smoothness error' 'compactness error' 'concavity error'
'concave points error' 'symmetry error' 'fractal dimension error'
'worst radius' 'worst texture' 'worst perimeter' 'worst area'
'worst smoothness' 'worst compactness' 'worst concavity'
'worst concave points' 'worst symmetry' 'worst fractal dimension']
보스턴 주택 가격
from sklearn.datasets import load_boston
boston = load_boston()
print("데이터의 형태:", boston.data.shape)데이터의 형태: (506, 13)X,y = mglearn.datasets.load_extended_boston()
print("X.shape:",X.shape)X.shape: (506, 104)
k-최근접 이웃
mglearn.plots.plot_knn_classification(n_neighbors=1)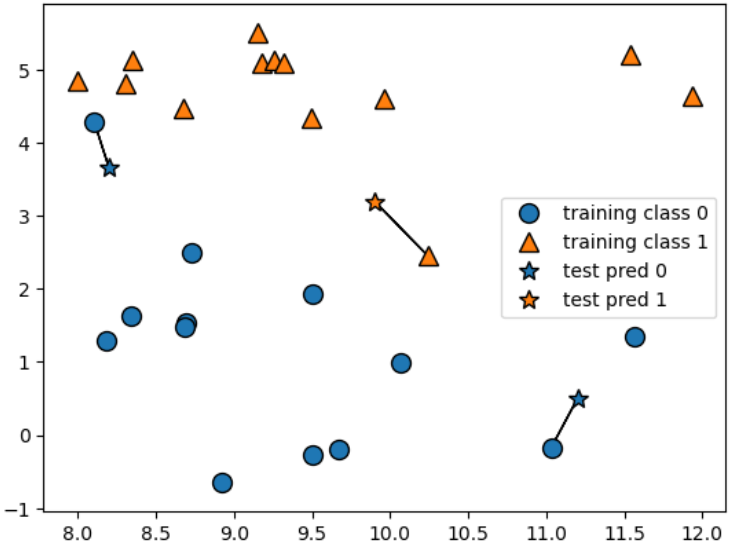
mglearn.plots.plot_knn_classification(n_neighbors=3)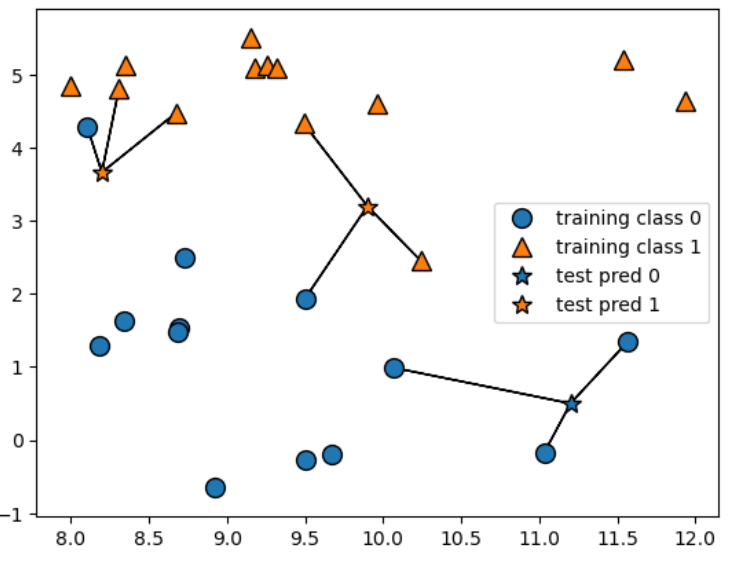
from sklearn.model_selection import train_test_split
X,y = mglearn.datasets.make_forge()
X_train, X_test, y_train, y_test = train_test_split(X,y,random_state=0)from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors=3)clf.fit(X_train,y_train)KNeighborsClassifier(n_neighbors=3)
print("테스트 세트 예측:",clf.predict(X_test))테스트 세트 예측: [1 0 1 0 1 0 0]
print("테스트 세트 정확도:{:.2f}".format(clf.score(X_test, y_test)))테스트 세트 정확도:0.86
KNeighborsClassifier
fig, axes = plt.subplots(1,3,figsize=(10,3))
for n_neighbors, ax in zip([1,3,9],axes):
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X,y)
mglearn.plots.plot_2d_separator(clf,X, fill=True, eps=0.5,ax=ax,alpha=.4)
mglearn.discrete_scatter(X[:,0],X[:,1],y, ax=ax)
ax.set_title("{}이웃".format(n_neighbors))
ax.set_xlabel("특성 0")
ax.set_ylabel("특성 1")
axes[0].legend(loc=3)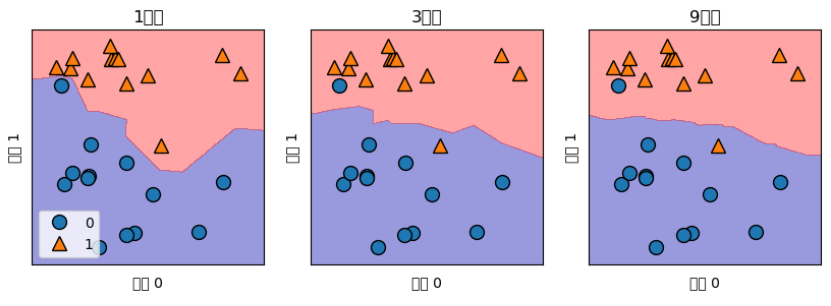
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test,y_train,y_test = train_test_split(cancer.data, cancer.target, stratify=cancer.target,random_state=66)
training_accuracy=[]
test_accuracy= []
neighbors_settings = range(1,11)
for n_neighbors in neighbors_settings:
clf=KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
training_accuracy.append(clf.score(X_train, y_train))
test_accuracy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, training_accuracy,label="훈련정확도")
plt.plot(neighbors_settings, test_accuracy,label="테스트 정확도")
plt.ylabel("정확도")
plt.xlabel("n_neighbors")
plt.legend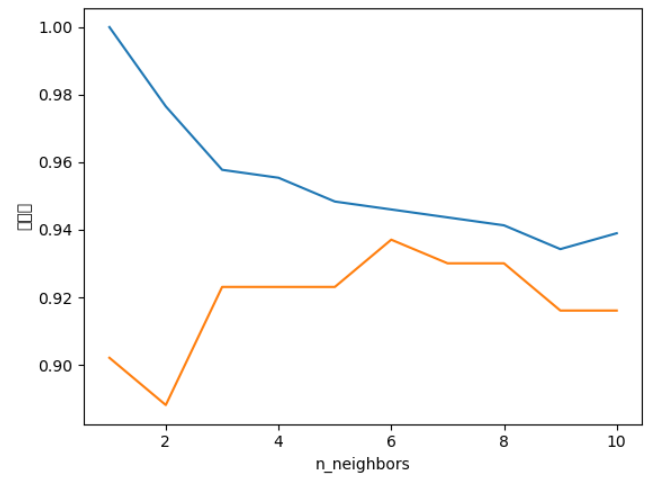
드디어 데이터 시각화에서 벗어남
딥러닝 딱대..

#ABC부트캠프 #부트캠프 #유클리드소프트 #파이썬 #고용노동부 #한국산업인력공단 #청년친화형 #ESG지원사업 #대전 #서포터즈 #python #Ai #Bigdata #cloud #대외활동 #대학생 #daily
'Language > Python' 카테고리의 다른 글
| [Python] 4-3) 머신러닝 - 결정트리.. (1) | 2023.04.13 |
|---|---|
| [Python] 4-2) 머신러닝 - 지도학습 알고리즘 (1) | 2023.04.13 |
| [Python] 3-2) 정규표현식, 워드클라우드 (0) | 2023.04.06 |
| [Python] 3-1) 데이터 수집 및 크롤링 (0) | 2023.03.30 |
| [Python] 2-5) Matplotlib 2 (0) | 2023.03.29 |
Comments