

생각하는 감쟈
[Python] 2-4) Data Frame 1 본문
11일차 (23.03.27)

데이터 프레임의 데이터 조작
import seaborn as sns
titanic = sns.load_dataset("titanic")
titanic.head()
iris = sns.load_dataset("iris")
iris
titanic = sns.load_dataset("titanic",nrows=10)
titanic.head()
titanic["age"]0 22.0
1 38.0
2 26.0
3 35.0
4 35.0
5 NaN
6 54.0
7 2.0
8 27.0
9 14.0
Name: age, dtype: float64나이만 추출
titanic.loc[titanic.sex == "female", "age"]1 38.0
2 26.0
3 35.0
8 27.0
9 14.0
Name: age, dtype: float64여성 age 추출
여성을 뽑고 거기서age를 추출
뽑아내기
인덱스 loc iloc
import numpy as np
import pandas as pd
s = pd.Series(range(10))
s[3] = np.nan
s0 0.0
1 1.0
2 2.0
3 NaN
4 4.0
5 5.0
6 6.0
7 7.0
8 8.0
9 9.0
dtype: float64s.count()결과 값 = > 9 NAn 값은 세지 않음
np.random.seed(2)
df = pd.DataFrame(np.random.randint(5, size=(4, 4)), dtype=float)
df.iloc[2, 3] = np.nan
df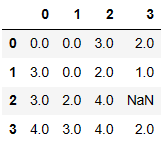
seed값이 없으면 실행할때 마다 매번 다름 값이 나옴 세팅할려면 일정 값으로 정하기
df["a"] =열 출력 / 행 뽑고 싶으면 df[1:4]
df.loc[] = "행 / df.loc[행][열] = 슬라이싱 필요 없음 문자값 접근
df.iloc[0] / df.iloc[0][1] : 숫자값 접근
df.count()0 4
1 4
2 4
3 3
dtype: int64열이 기본 축이 됨, ex) 0행의 데이터가 4개 있다
import seaborn as sns
titanic = sns.load_dataset("titanic")
titanic.head()
titanic.count()survived 891
pclass 891
sex 891
age 714
sibsp 891
parch 891
fare 891
embarked 889
class 891
who 891
adult_male 891
deck 203
embark_town 889
alive 891
alone 891
dtype: int64열 데이터 값을 계산해 줌
np.random.seed(1)
s2 = pd.Series(np.random.randint(6, size=100))
s2.tail()95 4
96 5
97 2
98 4
99 3
dtype: int32랜덤 값 0에서부터 5까지 100개 추출
s2.value_counts()1 22
0 18
4 17
5 16
3 14
2 13
dtype: int64각각의 값이 나온 횟수
df[3].value_counts()2.0 2
1.0 1
Name: 3, dtype: int643열을 출력 거기에 있는 값들이 옃개 씩 있나 확인.
정렬
정렬 기준 - 오르차순
내림 차순으로 하고 싶으면 (ascending=False) Flase로 입력
s2.value_counts().sort_index()0 18
1 22
2 13
3 14
4 17
5 16
dtype: int64s2.value_counts() => 데이터가 몇 개 인지 세 줌
인덱스의 기준으로 sort(오름차순 정렬) =>값기준 으로 하고싶으면 values로
s.sort_values()0 0.0
1 1.0
2 2.0
4 4.0
5 5.0
6 6.0
7 7.0
8 8.0
9 9.0
3 NaN
dtype: float64s2.value_counts().sort_index()2 13
3 14
5 16
4 17
0 18
1 22값기준 으로 하고싶으면 values로
s.sort_values()0 0.0
1 1.0
2 2.0
4 4.0
5 5.0
6 6.0
7 7.0
8 8.0
9 9.0
3 NaNs.sort_values(ascending=False)9 9.0
8 8.0
7 7.0
6 6.0
5 5.0
4 4.0
2 2.0
1 1.0
0 0.0
3 NaN내림차순 ascending=False
df.sort_values(by=1)
(by=1) : 1열을 기준으로 오름차순을 한다
df.sort_values(by=[1, 2])
(by=[1, 2]) : 첫번쨰 기준으로 정렬하고 혹시 같은 같이 있으면 2열로 기준을 잡아 정렬한다
연습문제)
sort_values 메서드를 사용하여 타이타닉호 승객에 대한
sex 인원수,age 인원수, class 인원수, alive 인원수를 구하라
np.random.seed(1)
df2 = pd.DataFrame(np.random.randint(10, size=(4, 8)))
df2
df2.sum(axis=1)0 35
1 34
2 41
3 42(axis=1) : 0=행 1=열
df2["RowSum"] = df2.sum(axis=1)
df2
df2.sum()0 24
1 33
2 25
3 24
4 15
5 10
6 5
7 16
RowSum 152df2.loc["ColTotal", :] = df2.sum()
df2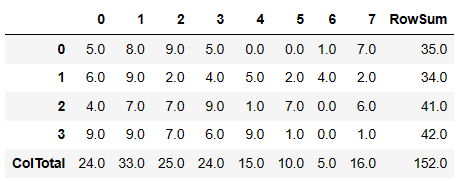
밑에 열 추가하기
연습문제)
타이타닉호 승객의 평균 나이를 구하라
titanic["age"].mean()결과 => 29.69911764705882
타이타닉호 승객중 여성 승객의 평균 나이를 구하라.
titanic.loc[titanic.sex=="female"]["age"].mean()결과 => 27.915708812260537
타이타닉호 승객중 1등실 선실의 여성 승객의 평균 나이를 구하라
titanic.loc[(titanic["class"]=="First")&(titanic["sex"]=="female")]["age"].mean()결과 =>34.61176470588235
apply 변환
df3 = pd.DataFrame({
'A': [1, 3, 4, 3, 4],
'B': [2, 3, 1, 2, 3],
'C': [1, 5, 2, 4, 4]
})
df3
df3.apply(lambda x: x.max() - x.min())A 3
B 2
C 4lambda : 이름이 없는 함수 값, 결과 값을 x로 리턴
apply 행,열 을 끈까지 계산
df3.apply(lambda x: x.max() - x.min(), axis=1)
0 1
1 2
2 3
3 2
4 1축 바꿔서 계산
df3.apply(pd.value_counts)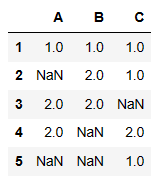
20살 기준으로 성인, 미성년자 구분
titanic["adult/child"] = titanic.apply(lambda r: "adult" if r.age >= 20 else "child", axis=1)
titanic.tail()
타이타닉호의 승객에 대해 나이와 성별의 의한 카테고리 열인 category1열을 만들어라
category 카테고리는 다음과 같이 정의된다
1 20살이 넘으면 성별을 그대로 사용한다
2 20살 미만이면 성별에 관계없이 "child"리고 한다.
titanic["category"] = titanic.apply(lambda r:r.sex if r.age >= 20 else "child", axis=1)
titanic.tail()
fillna 메서드
df3.apply(pd.value_counts).fillna(0.0)
fillna가 없으면 nan값이 나옴 그 nan값이 0.0으로 채워짐
astype 메서드
타이타닉호의 승객 중 나이를 명시하지 않은 고객은 나이를 명시한 고객의 평균 나이 값이 되도록
titanic 데이터 프레임을 고쳐라.
df3.apply(pd.value_counts).fillna(0).astype(int)
연습문제)
타이타닉호의 승객에 대해 나이와 성별에 의한 카테고리 열인 category2 열을 만들어라
category2 카테고리는 다음과 같이 정의된다
1 성별을 나타내는 문자열 male 또는 female로 시작한다
2 성별을 나타내는 문자열 뒤에 나이를 나타내는 문자여에 온다
3 에를 들어 27살 남성은 male27 값이 된다
titanic["category2"] = titanic.sex + titanic.age.astype(str)
titanic
#ABC부트캠프 #부트캠프 #유클리드소프트 #파이썬 #고용노동부 #한국산업인력공단 #서포터즈 #python #Ai #Bigdata #cloud #대외활동 #대학생 #daily
'Language > Python' 카테고리의 다른 글
| [Python] 2-5) Matplotlib 1 (0) | 2023.03.29 |
|---|---|
| [Python] 2-4) Data Frame 2 (1) | 2023.03.28 |
| [Python] 2-3) Pandas Series (1) | 2023.03.27 |
| [Python] 2-2) Jupyter Numpy (0) | 2023.03.23 |
| [Python] 2-1) Jupyter 기초 (0) | 2023.03.22 |
