
생각하는 감쟈
[Python] 2-3) Pandas Series 본문
9 일차 (23.03.27)
Pandas Series
obj = pd.Series([2.-7,4,10])
obj0 -5.0
1 4.0
2 10.0
dtype: float641차원 배열이 형태를 시리즈로 만들어줌 - key값 : value 값
obj.valuesarray([-5., 4., 10.])
obj.indexRangeIndex(start=0, stop=3, step=1)obj2 = pd.Series([2,-7, 4, 10], index = ['d','b','a','c'])
obj2d 2
b -7
a 4
c 10
dtype: int64시리즈를 만들때 값 넘겨주고 인덱스 따로 넣어주기
obj2.indexIndex(['d', 'b', 'a', 'c'], dtype='object')
obj2['a']결과 값 => 4
obj2['d']=6
obj2[['c','a','d']]c 10
a 4
d 6
dtype: int64obj2[obj2>0]d 6
a 4
c 10
dtype: int64obj2 * 2d 12
b -14
a 8
c 20
dtype: int64import numpy as np
np.exp(obj2)import numpy as np
np.exp(obj2)'b' in obj2결과값=> True
obj2에 b 인덱스값이 존재하는지
딕서너리 타입이여서 in 사용 가능
obj3 = obj2.reindex(['a','b','c','d'])
obj3a 4
b -7
c 10
d 6
dtype: int64reindex로 재배열 없는 인덱스는 NaN으로 나옴
pd.Series(range(10, 14))0 10
1 11
2 12
3 13
dtype: int64sdata = {'Ohio' : 3500, 'Texas' : 7100,'Oregon' : 6000, 'Utah' : 1200}
obj3 = pd.Series(sdata)
obj3Ohio 3500
Texas 7100
Oregon 6000
Utah 1200
dtype: int64사전형으로 데이터를 만듬
딕셔너리 객체를 시리즈로 생성 {key : value}
states = ['California', 'Ohio', 'Oregon','Texas']
obj4 = pd.Series(sdata, index=states)
obj4California NaN
Ohio 3500.0
Oregon 6000.0
Texas 7100.0
dtype: float64pd.isnull(obj4)California True
Ohio False
Oregon False
Texas False
dtype: boolisnull - null값인가?
pd.notnull(obj4)California False
Ohio True
Oregon True
Texas True
dtype: boolobj4.isnull()California True
Ohio False
Oregon False
Texas False
dtype: boolobj3+obj4California NaN
Ohio 7000.0
Oregon 12000.0
Texas 14200.0
Utah NaN
dtype: float64obj4.name = 'population'
obj4.index.name = 'state'
obj4state
California NaN
Ohio 3500.0
Oregon 6000.0
Texas 7100.0
Name: population, dtype: float64시리즈에 이름 설정 인덱스에도 가능
obj0 2
1 -7
2 4
3 10
dtype: int64obj.index = ['bob', 'steve','jeff','ryan']
objbob 2
steve -7
jeff 4
ryan 10
dtype: int64딕셔너리의 원소는 순서가 없으므로 순서를 정하고 싶을경우 인덱스를 리스트로 지정
2021년 2020년 인구데이터
s = pd.Series([9904312, 3448737, 2890451, 2466052],
index=["서울", "부산", "인천", "대구"])
s서울 9904312
부산 3448737
인천 2890451
대구 2466052
dtype: int64s2 = pd.Series({"서울": 9631482, "부산": 3393191, "인천": 2632035, "대전": 1490158},
index=["부산", "서울", "인천", "대전"])
s2부산 3393191
서울 9631482
인천 2632035
대전 1490158
dtype: int64ds = s - s2#인구증가
ds대구 NaN
대전 NaN
부산 55546.0
서울 272830.0
인천 258416.0
dtype: float64매칭되는 애들끼리만 가능함
s.values - s2.valuesarray([ 6511121, -6182745, 258416, 975894], dtype=int64)s.values s가 가지고 있는 값만 1차원 배열로 나옴
배열끼리 연산을 해주고 각각 자리가 같은 애들끼리 계산해줌
ds[ds.notnull()]부산 55546.0
서울 272830.0
인천 258416.0
dtype: float64rs = (s - s2) / s2 * 100
rs = rs[rs.notnull()]
rs부산 1.636984
서울 2.832690
인천 9.818107
dtype: float64
시리즈 인덱싱
s = pd.Series([9904312, 3448737, 2890451, 2466052],
index=["서울", "부산", "인천", "대구"])
s서울 9904312
부산 3448737
인천 2890451
대구 2466052
dtype: int64s[1], s["부산"]
s[1], s["부산"]
s[[0, 3, 1]]s[[0, 3, 1]]0서울 3대구 1부산 인덱스 추출
s[["서울", "대구", "부산"]]서울 9904312
대구 2466052
부산 3448737
dtype: int64s[(250e4 < s) & (s < 500e4)]부산 3448737
인천 2890451
dtype: int64인구가 250만 초과, 500만 미만인 경우
s[1:3]부산 3448737
인천 2890451
dtype: int643 미포함
s["부산":"대구"]부산 3448737
인천 2890451
대구 2466052
dtype: int64대구까지 포함 숫자랑 문자열 차이점
s.부산3448737대구 포함
for k, v in s.items():
print("%s = %d" % (k, v))서울 = 9904312
부산 = 3448737
인천 = 2890451
대구 = 2466052
데이터 갱신, 추가, 삭제
ds["부산"] = 1.63
ds대구 NaN
대전 NaN
부산 1.63
서울 272830.00
인천 258416.00
dtype: float64기존에 있는 값이면 수정
ds["서산"] = 1.63
ds대구 NaN
대전 NaN
부산 1.63
서울 272830.00
인천 258416.00
서산 1.63
dtype: float64없는 값이면 추가
del ds["서산"]
ds대구 NaN
대전 NaN
부산 1.63
서울 272830.00
인천 258416.00
dtype: float64삭제
ds.drop('부산')대구 NaN
대전 NaN
서울 272830.0
인천 258416.0
dtype: float64del, drop 삭제
del[] : 인덱스 요소 / drop() : 함수요소 삭제
DataFrame
DataFrame : 표 같은 스프레드시트 형식의 자료구조
각 컬럼은 다른 종류의 값을 담을 수 있다
- 우선 하나의 열이 되는 데이터를 리스트나 일차원 배열을 준비한다
- 이 각각의 열에 대한 이름을 키로 가지는 딕셔너리를 만든다
- 이 데이터를 DataFrame 클래스 생성자에 넣는다.
동시에 열방향 인덱스는 colums인수로, 행방향 인덱스는 index 인수로 지정한다
data = {
"2015": [9904312, 3448737, 2890451, 2466052],
"2010": [9631482, 3393191, 2632035, 2431774],
"2005": [9762546, 3512547, 2517680, 2456016],
"2000": [9853972, 3655437, 2466338, 2473990],
"지역": ["수도권", "경상권", "수도권", "경상권"],
"2010-2015 증가율": [0.0283, 0.0163, 0.0982, 0.0141]
}
columns = ["지역", "2015", "2010", "2005", "2000", "2010-2015 증가율"]
index = ["서울", "부산", "인천", "대구"]
df = pd.DataFrame(data, index=index, columns=columns)
df
사진 설명을 입력하세요.
df.valuesarray([['수도권', 9904312, 9631482, 9762546, 9853972, 0.0283],
['경상권', 3448737, 3393191, 3512547, 3655437, 0.0163],
['수도권', 2890451, 2632035, 2517680, 2466338, 0.0982],
['경상권', 2466052, 2431774, 2456016, 2473990, 0.0141]], dtype=object)df.columnsIndex(['지역', '2015', '2010', '2005', '2000', '2010-2015 증가율'], dtype='object')df.indexIndex(['서울', '부산', '인천', '대구'], dtype='object')df.index.name = "도시"
df.columns.name = "특성"
df
사진 설명을 입력하세요.
각각의 이름 설정
df.T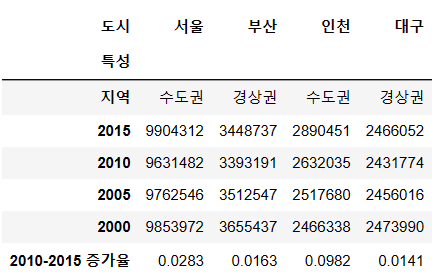
사진 설명을 입력하세요.

사진 설명을 입력하세요.
1
df["2010-2015 증가율"] = df["2010-2015 증가율"] * 100
df
사진 설명을 입력하세요.
2
df["2005-2010 증가율"] = ((df["2010"] - df["2005"]) / df["2005"] * 100).round(2)
df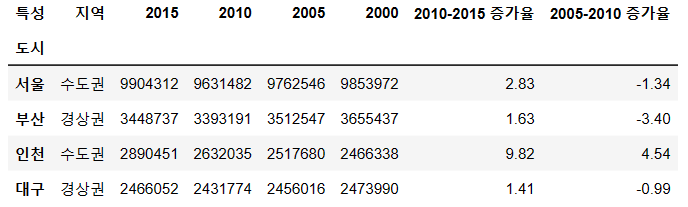
사진 설명을 입력하세요.
3
del df["2010-2015 증가율"]
df
사진 설명을 입력하세요.
연습문제)
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
|
이름 / 목록
|
수학
|
영어
|
과학
|
성별
|
|
홍길동
|
68
|
88
|
55
|
남자
|
|
성춘향
|
91
|
75
|
100
|
여자
|
|
전우치
|
86
|
72
|
86
|
남자
|
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
data = {
"수학" : [68,91,86],
"영어" : [88,75,72],
"과학" : [55,100,86],
"성별" : ["남자","여자","남자"]
}
columns = ["수학","영어","과학","성별"]
index = ["홍길동","성춘향","전우치"]
ex1 = pd.DataFrame(data, index=index, columns=columns)
ex1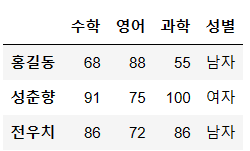
사진 설명을 입력하세요.
ex1.index.name = "이름"
ex1.columns.name = "목록"
ex1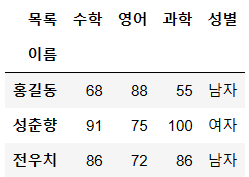
사진 설명을 입력하세요.
열 데이터 갱신, 추가, 삭제
df["2010-2015 증가율"] = df["2010-2015 증가율"] * 100
df
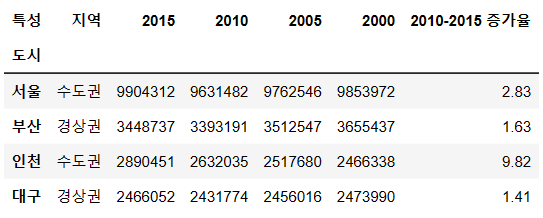
사진 설명을 입력하세요.
df["2005-2010 증가율"] = ((df["2010"] - df["2005"]) / df["2005"] * 100).round(2)
df
사진 설명을 입력하세요.
del df["2010-2015 증가율"]
df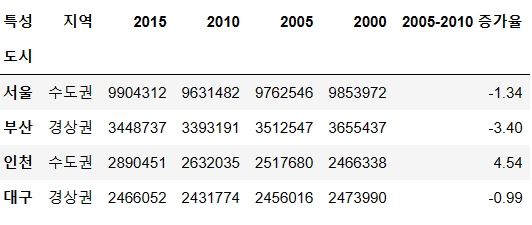
사진 설명을 입력하세요.
열 인덱싱
df["지역"]도시
서울 수도권
부산 경상권
인천 수도권
대구 경상권
Name: 지역, dtype: objectdf[["2010", "2015"]]

사진 설명을 입력하세요.
df[["2010"]]
사진 설명을 입력하세요.
type(df[["2010"]])type(df[["2010"]])df["2010"]도시 서울 9631482 부산 3393191 인천 2632035 대구 2431774 Name: 2010, dtype: int64
type(df["2010"])pandas.core.series.Series열 데이터프레임의 열 인덱스가 문자열 라벨을 가지고 있는 경우에는 순서를 나타내는 정수인덱스를 열 인덱실에 사용할 수 없다
원래부터 문자열이 아닌 정수형 열 인덱스를 가지는 경우에는 인덱스 값으로 정수를 사용할 수 있다
df2 = pd.DataFrame(np.arange(12).reshape(3, 4))
df2
사진 설명을 입력하세요.
df2[2]0 2
1 6
2 10
Name: 2, dtype: int32df2[[1, 2]]
사진 설명을 입력하세요.
행 인덱싱
행 단위로 인덱싱을 하고자 하면 항상 슬라이싱을 해야한다
df[:1]
사진 설명을 입력하세요.
df[1:2]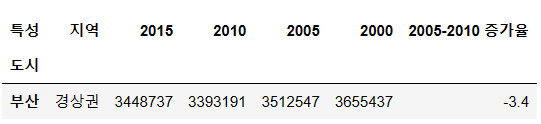
사진 설명을 입력하세요.
df[1:3]
사진 설명을 입력하세요.
df["서울":"부산"]
사진 설명을 입력하세요.
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
|
인덱싱 값
|
가능
|
결과
|
자료형
|
추가사항
|
|
라벨
|
o
|
열
|
시리즈
|
|
|
라벨 리스트
|
o
|
열
|
데이터 프레임
|
|
|
인덱스 데이터
(정수) |
X
|
|
|
열 라벨이 정수 - 라벨 인덱싱으로 인정
|
|
인덱스데이터
(정수)슬라이스 |
O
|
행
|
데이터 프레임
|
|
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
슬라이싱은 - 행을 추출 인덱스는 열을 추출한땐 슬라이싱: 사용 안됨 행 추출할때만
연습문제)

사진 설명을 입력하세요.
data = {
"국어":[10,20,30,40],
"영어":[10,20,30,40],
"수학":[10,20,30,40]
}
columns = ["국어","영어","수학"]
index = ["춘향","몽룡","향단","방자"]
ex2 = pd.DataFrame(data, index=index, columns=columns)
ex2
사진 설명을 입력하세요.
1
ex2['수학']춘향 10
몽룡 20
향단 30
방자 40
Name: 수학, dtype: int642)
ex2[["국어","영어"]]
사진 설명을 입력하세요.
3)
ex2['평균'] = ex2.mean(axis=1)
ex2
사진 설명을 입력하세요.
축은 기본 0값을 가짐 0은 열(밑으로) / 1은 행(옆으로)
4)
del ex2['평균'] #평균값 초기화
ex2["영어"]["방자"] = 80
ex2['평균'] = ex2.mean(axis=1) #axis=1 행
ex2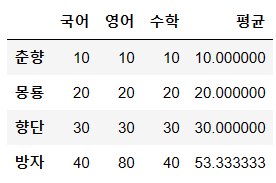
사진 설명을 입력하세요.
지금 평균의 값이 들어있음, 영어 점수를 바꾸면 경고가 뜸 그래서 실행 순서에 맞게 평균값을 없애주고 다시 구해줌
5)
ex2[:1]
사진 설명을 입력하세요.
6)
a = ex2.T # 축 변환
a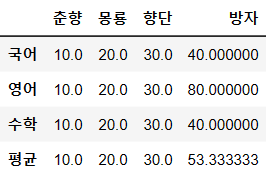
사진 설명을 입력하세요.
a['향단']국어 30.0
영어 30.0
수학 30.0
평균 30.0
Name: 향단, dtype: float64
데이터 입출력
- csv
- Excel
- HTML
- JSON
- HDF5
- SAS
- STATA
- SQL
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
- 6행 선택6행 다음에 행 추가
- 7행 선택7행 다음에 행 추가
- 8행 선택8행 다음에 행 추가
|
함수
|
설명
|
|
read_csv
|
구분자는 쉼표(,)
|
|
read_table
|
구분자는 탭(\)
|
|
read_fwf
|
고정폭(구분자 없음)
|
|
read_clipboand
|
클립보드, 웹페이지의 표 읽어올대 사용
|
|
read_excel
|
엑셀파일에서 표형식 데이터 읽기
|
|
read_hdf
|
HDFS파일에서 데이터 읽기
|
|
rad_html
|
HTML문서 내의 모든 테이블
|
|
read_json
|
JSon 문자열에서 데이터 읽기
|
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
%%writefile sample1.csv
c1, c2, c3
1, 1.11, one
2, 2.22, two
3, 3.33, threeOverwriting sample1.csvcsv - 컴마로 구분을 지음 주의 바람
pd.read_csv('sample1.csv')
사진 설명을 입력하세요.
인덱스가 없어도 자동으로 0,1,2 로 지정됨
%%writefile sample2.csv
1, 1.11, one
2, 2.22, two
3, 3.33, three
사진 설명을 입력하세요.
pd.read_csv('sample2.csv', names=['c1', 'c2', 'c3'])
사진 설명을 입력하세요.
pd.read_csv('sample1.csv', index_col='c1')
사진 설명을 입력하세요.
%%writefile sample3.txt
c1 c2 c3 c4
0.179181 -1.538472 1.347553 0.43381
1.024209 0.087307 -1.281997 0.49265
0.417899 -2.002308 0.255245 -1.10515
pd.read_table('sample3.txt', sep='\s+')
사진 설명을 입력하세요.
구분자가 쉼표가 아닌경우 sep지점, 길이가 정해져있지 않은 공백은 \s+를 넣어줌
%%writefile sample4.txt
파일 제목: sample4.txt
데이터 포맷의 설명:
c1, c2, c3
1, 1.11, one
2, 2.22, two
3, 3.33, threepd.read_csv('sample4.txt', skiprows=[0, 1])
사진 설명을 입력하세요.
%%writefile sample5.csv
c1, c2, c3
1, 1.11, one
2, , two
누락, 3.33, threedf = pd.read_csv('sample5.csv', na_values=['누락'])
df
사진 설명을 입력하세요.
pd.read_csv('sample5.csv',nrows=2)
몇줄만 읽기
상단에서 2줄 / head 위에서 5줄 taile 밑에서 5줄
파일 출력
df.to_csv('sample6.csv')!type sample6.csv,c1, c2, c3
0,1.0, 1.11, one
1,2.0, , two
2,, 3.33, three파일안에 잇는 값을 다 보여줌 = !type
df.to_csv('sample7.txt', sep='|')
!type sample7.txt|c1| c2| c3
0|1.0| 1.11| one
1|2.0| | two
2|| 3.33| threedf.to_csv('sample8.csv', na_rep='누락')
!type sample8.csv,c1, c2, c3
0,1.0, 1.11, one
1,2.0, , two
2,�늻�씫, 3.33, threedf.index = ["a", "b", "c"]
df
사진 설명을 입력하세요.
df.to_csv('sample9.csv', index=False, header=False)
!type sample9.csv1.0, 1.11, one
2.0, , two
, 3.33, threeindex=False, header=False : 데이터의 제목들 저장 x 값만 저장 됨
JSON 데이터
웹브라우저와 다른 애플릭케이션이 HTTP 요청으로 데이터를 보낼떄 사용
기본 자료형 : 객체(사전), 배열(리스트),(문자열), 숫자,불리언,널
객체의 키는 반드시 문자열
json 문자열을 파이썬 현태로 변환하기위해 json.loads
loc 인덱서
loc : 라벨값 기반의 2차원 인덱싱
- df. loc [ 행 인덱싱 값]
- df. loc [ 행 인덱
싱 값, 열 인덱싱 값]
행 인덱싱 값은 정수 또는 행 인덱스 데이터
열 인덱싱 값은 라벨 문자열
iloc : 순서를 나타내는 정수 기반의 2차원 인덱싱
df = pd.DataFrame(np.arange(10, 22).reshape(3, 4),
index=["a", "b", "c"],
columns=["A", "B", "C", "D"])
df
사진 설명을 입력하세요.
df.loc["a"]A 10
B 11
C 12
D 13
Name: a, dtype: int32하나의 인덱싱 값
df.loc["b":"c"]
사진 설명을 입력하세요.
인덱스 슬라이스
df["b":"c"]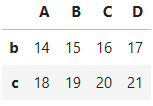
사진 설명을 입력하세요.
df.loc[["b","c"]]
사진 설명을 입력하세요.
df.A > 15a False
b False
c True
Name: A, dtype: booldf.loc[df.A > 15]
사진 설명을 입력하세요.
def select_rows(df):
return df.A > 15
select_rows(df)a False
b False
c True
Name: A, dtype: bool
df["A"] => A열 출력 df[1:3] = >1행과 3행
df.loc["A"] => A행 출력 df.loc[1:3] => 1,2,3행 출력
df2 = pd.DataFrame(np.arange(10, 26).reshape(4, 4), columns=["A", "B", "C", "D"])
df2
사진 설명을 입력하세요.
df2.loc[1:2]
사진 설명을 입력하세요.
- 0열 선택0열 다음에 열 추가
- 1열 선택1열 다음에 열 추가
- 2열 선택2열 다음에 열 추가
- 3열 선택3열 다음에 열 추가
- 4열 선택4열 다음에 열 추가
- 0행 선택0행 다음에 행 추가
- 1행 선택1행 다음에 행 추가
- 2행 선택2행 다음에 행 추가
- 3행 선택3행 다음에 행 추가
- 4행 선택4행 다음에 행 추가
- 5행 선택5행 다음에 행 추가
- 6행 선택6행 다음에 행 추가
- 7행 선택7행 다음에 행 추가
|
인덱싱 값
|
가능
|
결과
|
자료형
|
추가사항
|
|
행 인덱스 값(정수)
|
o
|
행
|
시리즈
|
|
|
행 인덱스 값(정수)슬라이스
|
o
|
행
|
데이터프레임
|
loc가 없는 경우와 같음
|
|
행 인덱스 값(정수)
리스트 |
o
|
행
|
데이터프레임
|
|
|
불리언 시리즈
|
o
|
행
|
데이터프레임
|
시리즈의 인덱스가 데이터프레임의 행인덱스와 같아야 함
|
|
불리언 시리즈를 반환하는 함수
|
o
|
행
|
|
|
|
열 라벨
|
x
|
|
|
loc가 없는 경우에만 쓸 수 있다
|
|
열 라벨 리스트
|
x
|
|
|
loc가 없는 경우에만 쓸 수 있다.
|
- 셀 병합
- 행 분할
- 열 분할
- 너비 맞춤
- 삭제
df.loc["a", "A"]결과 => 10
df.loc["b":, "A"]b 14
c 18
Name: A, dtype: int32df.loc["a", :]A 10
B 11
C 12
D 13
Name: a, dtype: int32a부터 다
df.loc[["a", "b"], ["B", "D"]]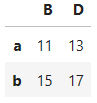
사진 설명을 입력하세요.
df.loc[df.A > 10, ["C", "D"]]
사진 설명을 입력하세요.
iloc인덱서
순서를 나타내는 정수인덱스만 받음
df.iloc[0, 1]결과값 => 11
df.iloc[:2, 2]a 12
b 16
Name: C, dtype: int32df.iloc[0, -2:]C 12
D 13
Name: a, dtype: int32df.iloc[2:3, 1:3]
사진 설명을 입력하세요.
df.iloc[-1]A 18
B 19
C 20
D 21
Name: c, dtype: int32df.iloc[-1] = df.iloc[-1] * 2
df
사진 설명을 입력하세요.

여긴 어디 나는 누구..........
#ABC부트캠프 #부트캠프 #유클리드소프트 #파이썬 #python #고용노동부 #한국산업인력공단
'Language > Python' 카테고리의 다른 글
| [Python] 2-4) Data Frame 2 (1) | 2023.03.28 |
|---|---|
| [Python] 2-4) Data Frame 1 (0) | 2023.03.28 |
| [Python] 2-2) Jupyter Numpy (0) | 2023.03.23 |
| [Python] 2-1) Jupyter 기초 (0) | 2023.03.22 |
| [Python] 타자 게임 만들기 (2) | 2023.03.20 |